Organisation physique#
Avant de discuter de mémoire volatile, il est important de comprendre les bases du fonctionnement d’un ordinateur. Un PC est composé de plusieurs composants électroniques et de périphériques qui interagissent ensemble. Un des composants principaux, la carte mère, permet la communication entre tous ces composants. Ces channels de communication sont généralement appelés computer busses.
CPU#
Les composants principaux sur la carte mère sont le CPU - qui exécute des suites d’instructions - et la mémoire volatile - qui stocke temporairement les programmes et leurs données. Le CPU accède à la mémoire pour y obtenir les instructions à exécuter.
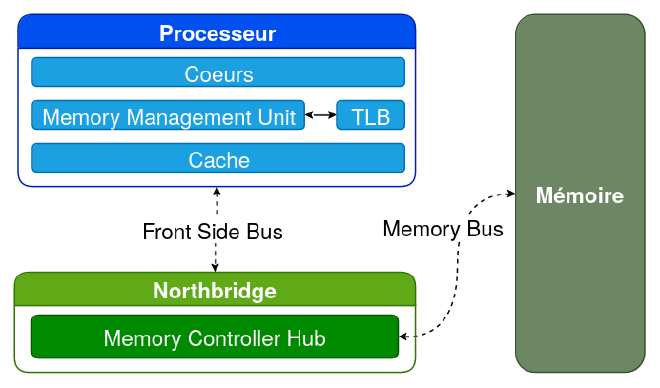
Lire depuis la mémoire est souvent très lent comparé à la mémoire interne du CPU, en conséquence les systèmes modernes adoptent plusieurs couches de mémoire très rapides : les caches.
Chaque niveau de cache (L1, L2, …) est plus lent que son prédécesseur mais comporte plus d’espace. Dans la plupart des systèmes, ces caches sont implémentés directement dans le processeur et chacun de ses coeurs. Si une donnée est demandée mais pas trouvée dans un cache, elle doit-être récupérée depuis le cache de second niveau ou la mémoire principale.
Memory Management Unit (MMU)#
Le MMU (Unité de Gestion de la Mémoire) est un composant hardware qui convertit les adresses virtuelles utilisées par le processeur en adresses physiques. Pour effectuer cette tâche, le MMU doit être configuré à l’aide de registres système spéciaux, tandis que des structures en mémoire maintenant la correspondance virtuelle-physique doivent être définies et continuellement mises à jour par le système d’exploitation.
En cas d’échec du MMU pour résoudre une adresse virtuelle demandée, il déclenche une interruption pour signaler au système d’exploitation de mettre à jour les structures en mémoire associées.
Le processus de traduction peut impliquer jusqu’à deux traductions distinctes, toutes deux effectuées par le MMU : la segmentation, qui convertit des adresses virtuelles en adresses segmentées, et la pagination, qui convertit des adresses segmentées en adresses physiques. Certaines architectures utilisent l’une ou l’autre, tandis que d’autres utilisent les deux.
Ces points seront détaillés dans la suite de l’article.
En général, lors du démarrage du système, le MMU est virtuellement désactivé et toutes les adresses virtuelles sont transformées de manière identique en adresses physiques. Cela permet au système d’exploitation de démarrer dans un environnement mémoire simplifié et de lui donner le temps de configurer/activer correctement le MMU avant de lancer d’autres processus.
Translation Lookaside Buffer (TLB)#
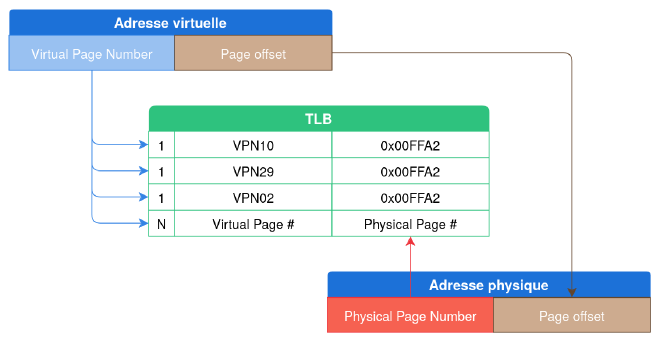
Une traduction d’adresse peut demander plusieurs lectures de la mémoire, et les opérations sont lentes. Alors, le processeur utilise un cache spécial appelé le Translation Lookaside Buffer (TLB). Avant de commencer une traduction, le MMU vérifie si les TLBs contiennent une adresse virtuelle déjà résolue et, le cas échéant, retournent directement les adresses physiques correspondantes.
Direct Memory Access#
Pour améliorer les performances des systèmes modernes, il existe des composants I/O qui ont la capacité de transférer directement de la mémoire stockée dans la RAM sans l’intervention du CPU : la Direct Memory Access (DMA). Avant que DMA soit inventé, le processeur s’occupait de chaque transfert de mémoire. Pour de gros transferts de données, le CPU devient rapidement un goulot d’étranglement. Sur les architectures modernes, le CPU peut initier un transfert de données en autorisant le contrôleur DMA à gérer le transférer. Un périphérique peut aussi faire un transfert indépendamment du CPU.
Mis à part son impact flagrant sur les performances, la DMA est aussi importante en forensics mémoire car elle permet d’accéder directement à la mémoire physique à partir d’un périphérique sans exécuter de programmes tiers sur la machine.
Je vous recommande l’article Malekal - DMA ou le post Geekforgeeks - DMA pour en apprendre plus.
Random Access Memory (RAM)#
La mémoire principale d’une machine est implémentée avec la Random Access Memory (RAM) qui stocke le code et les données associées que le CPU manipule. A contrario d’un Sequential Access Storage qui lit les données séquentiellement, le Random Access réfère à la caractéristique d’avoir un temps d’accès constant peu importe où la donnée se trouve sur le composant.
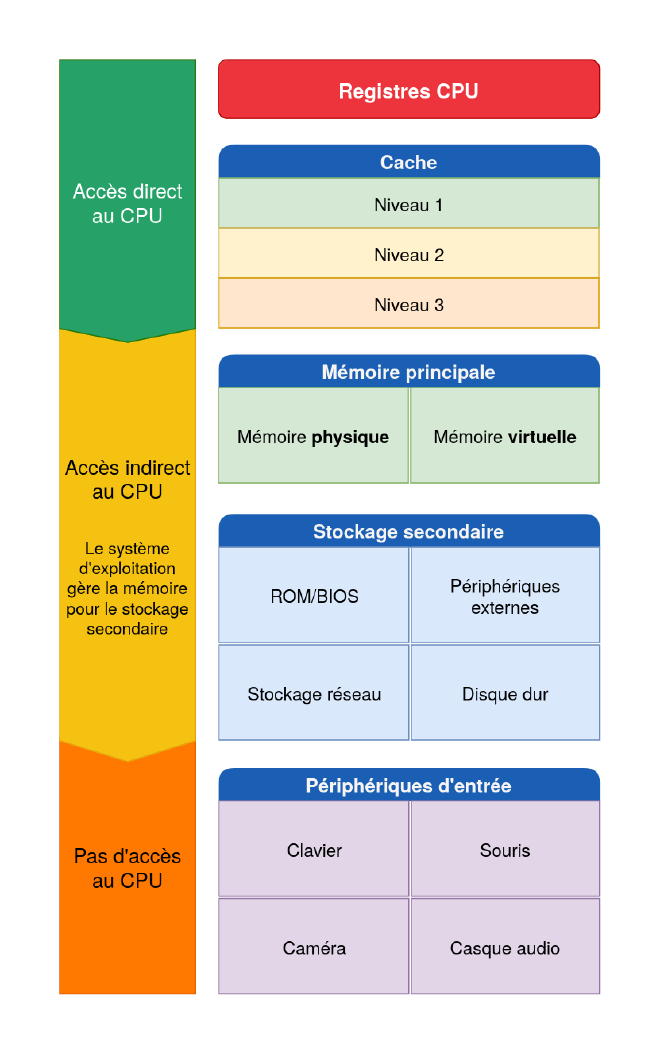
La mémoire principale est aussi appelée Dynamic RAM (DRAM). Elle est dynamique car elle utilise le différentiel entre un condensateur chargé et déchargé pour stocker un bit de donnée. Pour qu’il reste chargé, celui-ci doit être régulièrement rechargé par le contrôleur de mémoire (voir figure 1).
La RAM est appelée mémoire volatile car elle requiert de l’énergie pour que la donnée reste accessible. Lorsque la machine est éteinte, toutes les données sont perdues. Ou est-ce vraiment le cas ? L’étude Lest We Remember: Cold Boot Attacks on Encryption Keys démontre que la RAM reste chargée pendant quelques secondes - voire minutes - après la perte d’énergie.
Organisation logique#
Afin de pouvoir extraire des structures de la mémoire physique, on doit avoir une vue claire du modèle de programmation qu’utilise le CPU pour accéder à la mémoire. Nous avons vu la partie hardware, on va maintenant se concentrer sur la partie logique de l’organisation de la mémoire qui est exposée au système d’exploitation.
Pour que le CPU puisse exécuter des instructions et accéder aux données stockée dans la mémoire principale, il doit référencer une adresse unique. Une adresse peut-être de 64 bits (8 octets) ou 32 bits (4 octets) selon l’architecture.
L’espace d’adressage unique et continu qui est exposé à un programme en cours d’exécution est appelé Linear Address Space, ou plus couramment Virtual Address Space (VAS). On utilise le terme Physical Address Space (PAS) pour référer aux adresses de la mémoire physique. Ces adresses physiques sont obtenues par translation à partir des adresses virtuelles en utilisant une ou plusieurs page tables (agglomérat d’octets variable en taille selon les systèmes (4k, 8k, …)).
Mémoire virtuelle#
L’abstraction de la mémoire virtuelle offre de nombreux avantages, permettant aux programmes d’être écrits comme s’ils avaient un accès complet et illimité à la mémoire principale, indépendamment de leur utilisation et de la présence d’autres programmes. Cela permet d’exécuter plusieurs processus en même temps sans se soucier de la configuration réelle de la mémoire physique, qui peut changer d’une machine à l’autre. La mémoire virtuelle permet également d’isoler et de protéger les processus en empêchant les programmes malicieux, non autorisés ou mal programmés d’accéder à la mémoire d’autres programmes en cours d’exécution.
Ce système permet également à un programme d’allouer de la mémoire au-delà des limites du PAS en mappant une partie du VAS d’un processus dans un second stockage (typiquement un SSD/HDD, voir memory swap).
Cette abstraction est mise en œuvre dans différentes architectures en s’appuyant sur deux méthodes différentes :
- la segmentation
- la pagination
Segmentation#
La segmentation, la plus ancienne des deux méthodes, a été développée à l’origine pour organiser et protéger les programmes en cours d’exécution. Son objectif est de diviser le VAS d’un processus en une ou plusieurs unités logiques, appelées segments, de tailles et d’autorisations d’accès différentes en les mappant dans un autre espace d’adressage appelé Segmented Address Space (SAS).
En général, les segments suivent la structure interne du programme qu’ils représentent : un processus peut être divisé, par exemple, en deux segments différents contenant respectivement le code et les données. Par contre, la segmentation ne permet pas une utilisation optimale de la mémoire disponible : si on map des segments de plusieurs programmes directement sur la mémoire physique, la PAS commence à se fragmenter et, à un moment donné, il est impossible d’allouer de nouveaux morceaux de taille suffisante pour accueillir de nouveaux segments. Pour résoudre ce problème, nous devons d’abord introduire le concept de page.
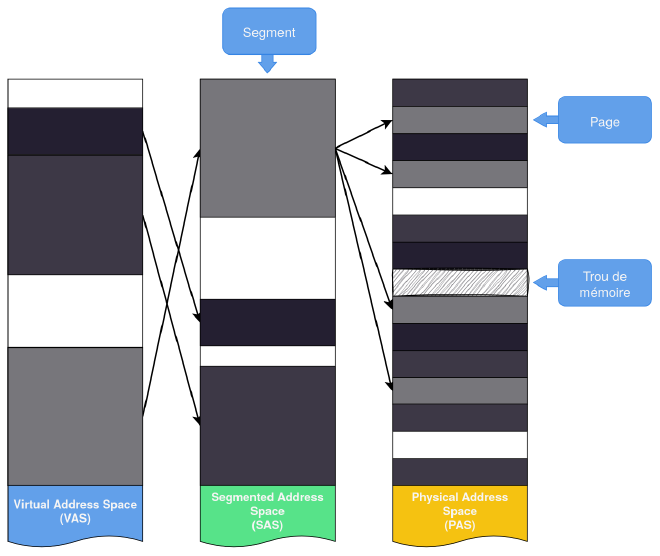
Pagination#
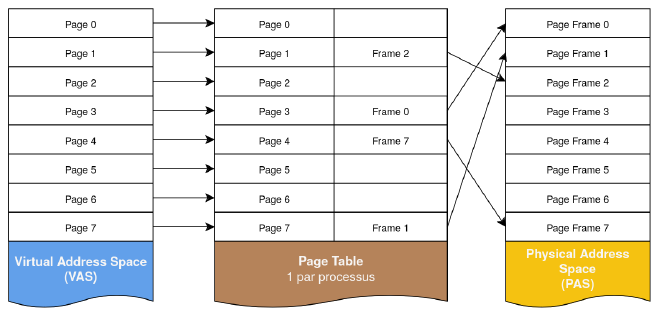
Une page est un bloc de mémoire continu de taille fixe (et généralement petite : 4k, 8k, …). Ensuite, nous divisons le SAS en un ensemble de pages - appelées pages virtuelles - et nous définissons un moyen de les faire correspondre aux pages du PAS (appelées pages physiques ou page frames), comme le montre la figure 4.
Cette technique, appelée pagination, réduit considérablement la fragmentation de la mémoire physique et contribue à maximiser l’utilisation des ressources disponibles. Il est important de comprendre que la segmentation et la pagination nécessitent des structures de données en mémoire, ou des registres CPU dédiés, qui doivent être configurés par le système d’exploitation et utilisés par le MMU.
Avant de voir les techniques de pagination les plus courantes sur la majorité des architectures, il faut décrire ce que sont les page tables, les page directory tables et les huge pages.
Les page tables sont des structures de données utilisées dans un système avec de la mémoire virtuelle. Elle permet d’établir une correspondance entre les adresses virtuelles et les adresses physiques.
Le numéro de page d’une adresse est généralement déterminé à partir des bits les plus significatifs de l’adresse ; les bits restants donnent l’offset de l’emplacement de la mémoire dans la page. La page table est normalement indexée par numéro de page et contient des informations indiquant si la page se trouve actuellement dans la mémoire principale et où elle se trouve dans la mémoire principale ou sur le disque (avec certains flags que nous verrons au prochain article).
Etant donné que les page tables ne peuvent pas contenir toutes les adresses du VAS, on a recourt aux page directory tables. Celles-ci sont aussi des structures de données, et ses entrées pointent vers des pages tables. Celà permet d’avoir un second niveau (voire plus selon les architectures).
Les huge pages sont principalement utilisées pour la gestion de la mémoire virtuelle sur Linux. Comme leur nom l’indique, elles permettent de gérer des pages de taille importante dans la mémoire, en plus de la taille de page standard de 4 Ko. Il est possible de définir des pages d’une taille allant jusqu’à 1 Go !
Au démarrage du système, les applications peuvent réserver des parties de la mémoire avec des huge pages. Ces parties de la mémoire ne seront jamais transférées dans le swap, celà permet d’améliorer considérablement les performances des applications.
Utiliser des pages de grande taille permet simplement d’avoir besoin de moins de pages. Cela réduit considérablement le nombre de page tables à charger par le kernel. Cela améliore les performances du kernel car le système en a moins à gérer, et donc moins de lecture/écriture pour y accéder et les maintenir.
La suite au prochain article !
Sources#
Beaucoup des diagrammes et du texte présenté sont inspirés des sources suivantes :
- The Art of Memory Forensics
- In the Land of MMUs: Multiarchitecture OS-Agnostic Virtual Memory Forensics
- Practical Memory Forensics
- What is Virtual Memory ? - All About Circuits
- What is huge pages in Linux - KernelTalks
- Translation Caching: Skip, Don’t Walk (the Page Table)
- Page Tables - The Linux Kernel
- Memory management in operating system - GeekforGeeks
- Exploring Virtual Memory and Page Structures - xenoscr.net